SceneTransporter: Optimal Transport-Guided Compositional Latent Diffusion for Single-Image Structured 3D Scene Generation
Abstract
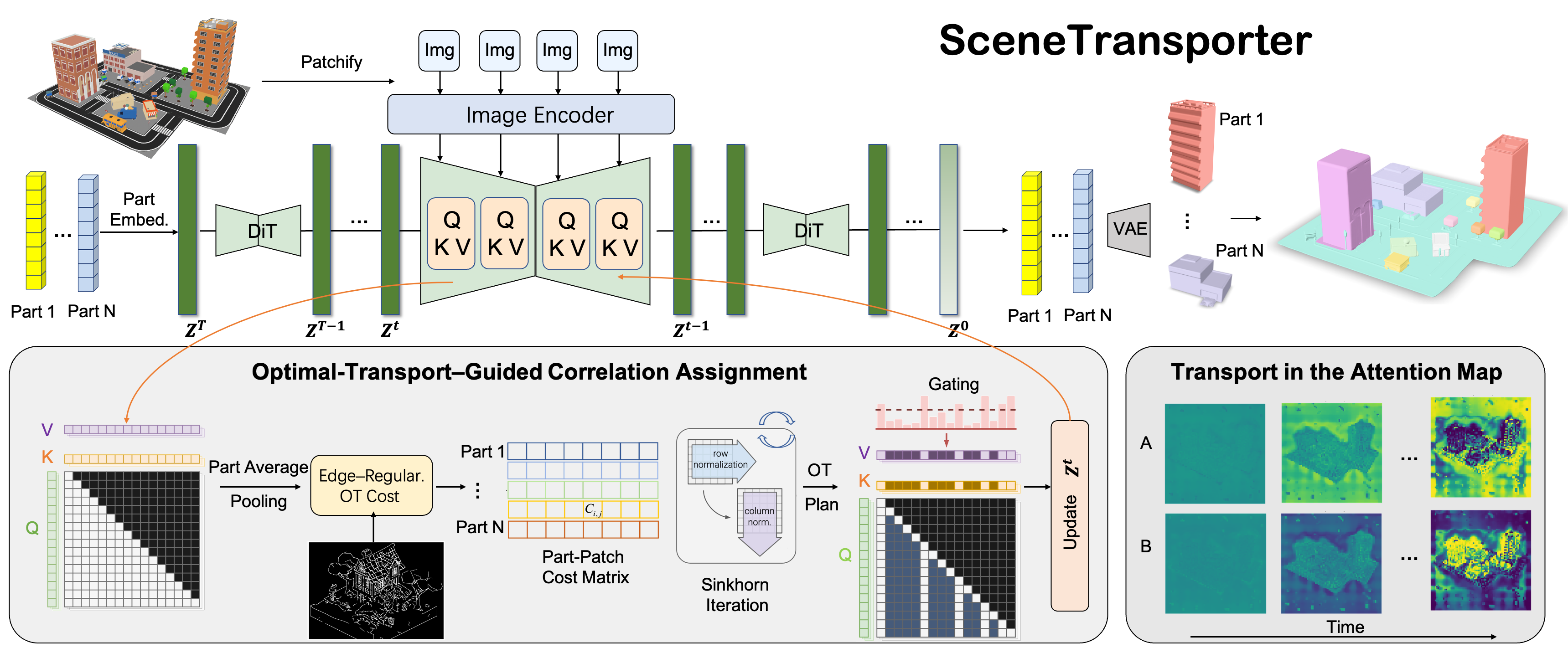
We introduce SceneTransporter, an end-to-end framework for structured 3D scene generation from a single image. While existing methods generate part-level 3D objects, they often fail to organize these parts into distinct instances in open-world scenes. Through a debiased clustering probe, we reveal a critical insight: this failure stems from the lack of structural constraints within the model's internal assignment mechanism. Based on this finding, we reframe the task of structured 3D scene generation as a global correlation assignment problem. To solve this, SceneTransporter formulates and solves an entropic Optimal Transport (OT) objective within the denoising loop of the compositional DiT model. This formulation imposes two powerful structural constraints. First, the resulting transport plan gates cross-attention to enforce an exclusive, one-to-one routing of image patches to part-level 3D latents, preventing entanglement. Second, the competitive nature of the transport encourages the grouping of similar patches, a process that is further regularized by an edge-based cost, to form coherent objects and prevent fragmentation. Extensive experiments show that SceneTransporter outperforms existing methods on open-world scene generation, significantly improving instance-level coherence and geometric fidelity.
Interactive Results
Comparison Methods
MIDI
PartCrafter
PartPacker
📷 Real-World Images 📷
We evaluated our model using real-world object images from the DL3DV-10K dataset. Since our model was trained on rendered images from Objaverse, we observed that directly testing it on real-world images led to suboptimal performance due to the domain gap.
To address this issue, we stylized the input images to resemble 3D renderings before feeding them into the model, which significantly improved the results. We used GPT-5's raw image transformation feature with the following prompt: "Preserve all details and perform image-to-image style transfer to convert the image into the style of a 3D rendering (Objaverse-style rendering)."












Related Links
There are a lot of excellent works that are related to our works.
PartPacker: Efficient Part-level 3D Object Generation via Dual Volume Packing
PartCrafter: Structured 3D Mesh Generation via Compositional Latent Diffusion Transformers
MIDI: Multi-Instance Diffusion for Single Image to 3D Scene Generation